20 years work in 20 minutes
|
(plus two demos)
Hamish Cunningham,
University of Sheffield

|
Contents
- 1. Background: the GATE family
- Developer, Embedded
- Teamware, Process
- Cloud
- KIM, OWLIM, Linked Data
- Mímir
- [Wiki]
2. Demos
- [an IDE for text analysis specialists]
- [collaborative manual annotation workflows]
- GATECloud.net
- Mímir: a mixed-mode index server
[3. Case studies]
- [IARC: the WHO's cancer lab]
- [TNA: UK National Archives]
- [SLaM: NHS clinical records mining]
4. A lifecycle for text analysis
|
Expensive IR systems
Value, volume
- if you have content that is sufficiently high value or low volume then you
can use expensive methods to help people find, browse or abstract over that
content
- those expensive methods include building symbolic models (taxonomic, logical,
conceptual, semantic...) of the subject matter and annotating content with
references to those models
Social vs. technological success factors
- the factors that influence success come in at least these two types:
- technological: the expressivity of the modelling languages and the quality
of the annotation algorithms, and of the indexing, search and browsing tools
- social: the level of expertise and the quantity of time and effort
deployed by the people building models and extraction patterns (or creating
training data and running learning algorithms), or tuning indices or user
interfaces
- GATE is a family of tools that are particularly relevant to reducing the time
and effort of skilled staff (or the social costs) involved in developing and
maintaining expensive information retrieval and management systems, while
attempting to stay close to the state of the technological art (sometimes by
favouring interoperation and reuse over innovation or reinvention)
- over the last decades the GATE team have created tools to cover the full
lifecycle of retrieval approaches that are based on information extraction
- the rest of the talk = a summary, then demos of our newest stuff
The GATE Family
- an architecture
- an IDE: GATE Developer: an integrated development environment for language
processing components bundled with a widely used Information Extraction system
and a comprehensive set of
other plugins
- a framework: GATE Embedded: an object library optimised for inclusion in
diverse applications giving access to all the services used by GATE Developer
and more
- used worldwide by thousands of scientists, companies, teachers and students
(>30k downloads per year at present, not counting SVN)
- open source (LGPL), 100% java
- a web app: GATE Teamware a collaborative annotation environment for
factory-style semantic annotation projects built around a workflow engine
- a process: not "get this software and it will revolutionise your life" but
"this is how to implement robust and maintainable services"
- GATE Cloud: a parallel and distributed service infrastructure running on
Amazon EC2
- GATE Mímir: (Multi-paradigm Information Management Index and Repository) a
scaleable multiparadigm index built on Ontotext's
semantic repository family, GATE's
annotation structures database plus full-text indexing from
MG4J
- and finally...
- related tools from Ontotext (OWLIM, KIM, Linked Data endpoints)
- GATE Wiki
- a community
GATE Developer (1)
Motivation: 1990s apparatus envy: physicists had supercolliders; medics had
MRI scanners; language processing researchers had.... Perl?
- A specialist Integrated Development Environment for language engineering R&D
- Analogous to
- Eclipse or Netbeans for programmers
- Mathematica or SPSS for maths and stats
- Visualisation and editing text, annotations, ontologies, parse trees, etc.
- Constructing applications from components
- Measurement, evaluation, benchmarking
- Etc., etc.
GATE Developer (2)
GATE Embedded (1)
Object-oriented Java framework. Architectural principles:
- Non-prescriptive, theory neutral (strength and weakness)
- Re-use, interoperation, not reimplementation (e.g. diverse XML support,
integration of Protégé, OWLIM, Weka, Lingpipe, OpenNLP, SVM Lite, etc.
etc....)
- (Almost) everything is a component, and component sets are user-extendable
- (Almost) all operations are available both from API (Embedded) and GUI
(Developer)
CREOLE: a Collection of REusable Objects for Language Engineering
- GATE components: modified Java Beans with XML configuration
- The minimal component = 10 lines of Java, 10 lines of XML, 1 URL
GATE Embedded (2)
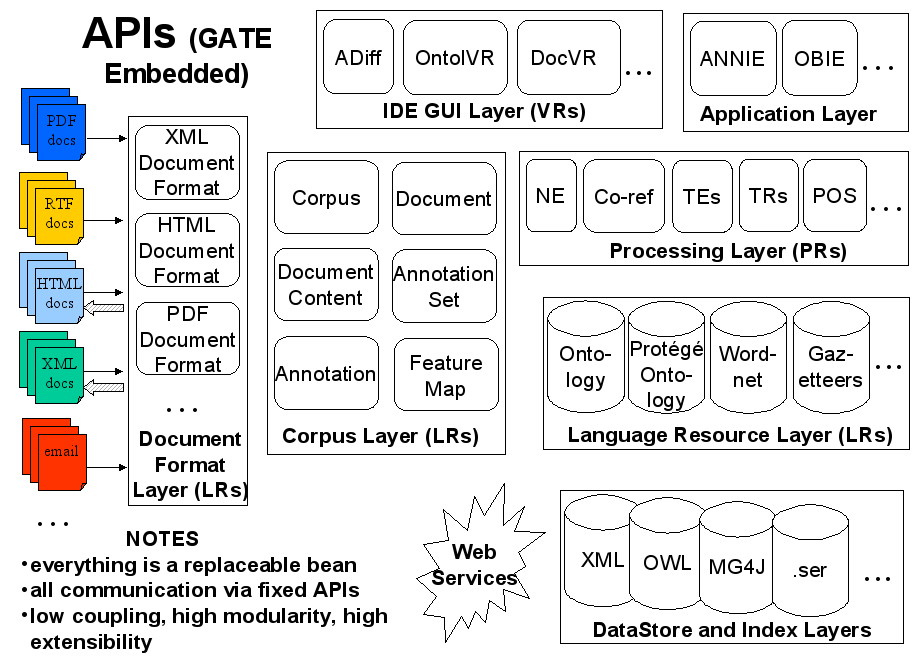
GATE Embedded (3)
- persistence, visualisation and editing
- a finite state transduction language (JAPE)
- extraction of training instances for machine learning (ML)
- pluggable ML implementations (Weka, YALE, SVM, ...)
- components for language processing, e.g. parsers, machine learning tools,
stemmers, a few IR tools (Lucene, GYM query plugins), IE components for
various languages...
- bundled with a very widely used Information Extraction system (ANNIE)
- MUC, TREC, ACE, DUC, Pascal, NTCIR, etc.
- simple API for RDF or OWL (metadata) via OWLIM
- kitchen sink
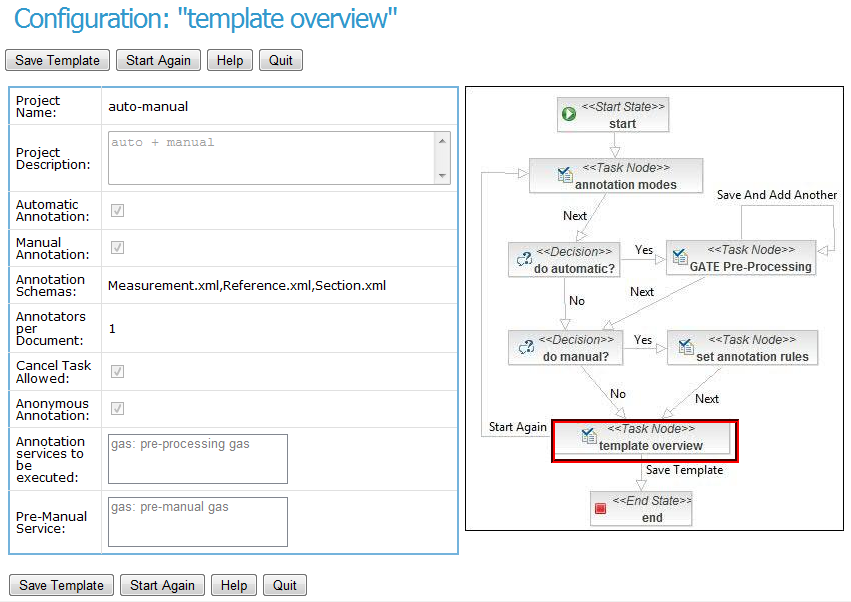
Process, workflow, GATE Teamware (1)
|
A typical annotation project:
- client discussion, task exploration, draft extraction specification
- manual annotation, inter-annotator agreement, iterate the task spec
- prototype a machine solution
- more manual annotation for training and test data (gold standard)
- implement production solution
- more manual annotation for quality control, maintenance, adaptation...
| |
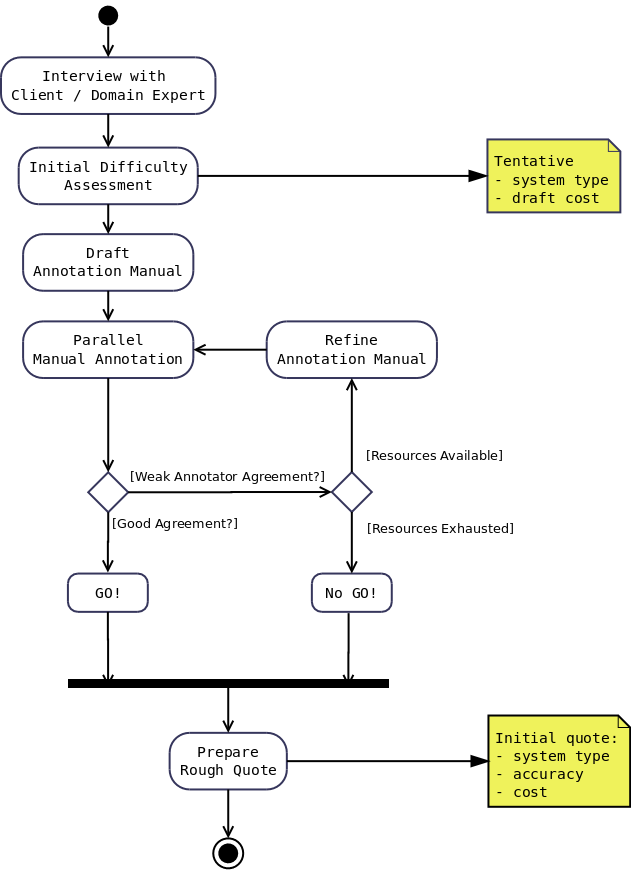
|
Process, workflow, GATE Teamware (2)
- The GATE process is a set of steps to follow in the definition, prototyping,
development, deployment and maintenance of semantic annotation processes.
- GATE Teamware is a workflow-based web engine supporting these processes.
- Based on JBoss Process Management engine (BPEL compatible)
- Teamware supports marshalling the manual annotation team, job allocation,
quality control, training, communication, process monitoring...
- Case study: Lighthouse Group runs teams of
annotators in Cebu (Philippines), e.g. supplying 10,000 hours to Khresmoi
project for on-line medical information.
Teamware (3): workflow configuration
Teamware (4): process monitoring
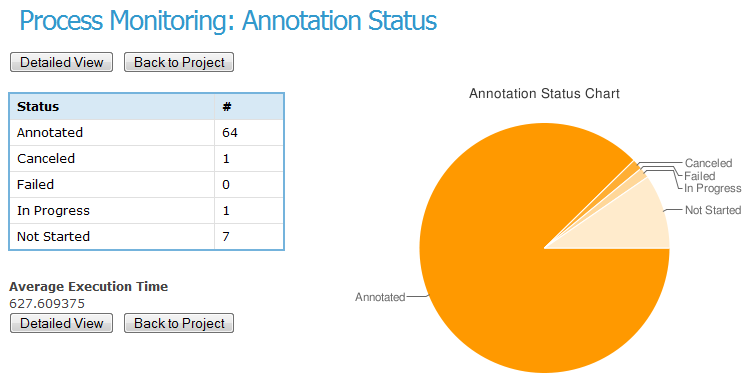
Teamware (5): quality control
Teamware (6): staff communication
GATE Cloud (1): the marketing BS
Cloud computing means many things in many contexts. On GATECloud.net it
means:
- zero fixed costs: you don't buy software licences or server hardware, just
pay for the compute time that you use
- near zero startup time: in a matter of minutes you can specify, provision
and deploy the type of computation that used to take months of planning
- easy in, easy out: if you try it and don't like it, go elsewhere! you can
even take the software with you, it's all open source
- someone else takes the admin load:
- the GATE team from the University of Sheffield make sure you're running the best of breed
technology for text, search and semantics
- cloud providers' data center managers (e.g. at Amazon Inc.) make sure the hardware and operating platform for your work
is scaleable, reliable and cheap
GATE Cloud (2): engineering
- parallel execution engine of automatic annotation processes + distributed
execution of parallel engine
- scalability: auto-scaling of processor swarms running on top of AWS EC2
- flexibility: parameters configure behaviour, select the GATE application
being executed, the input protocol used reading documents, the output protocol
used for exporting the resulting annotations, ...
- robustness: jobs run unattended over large data sets
- extensively tested and profiled (no memory leaks)
- errors and exceptions that occur during processing are trapped and reported
- if the process crashes (e.g. hardware failure), can be restarted and resumes
execution where it left off
|
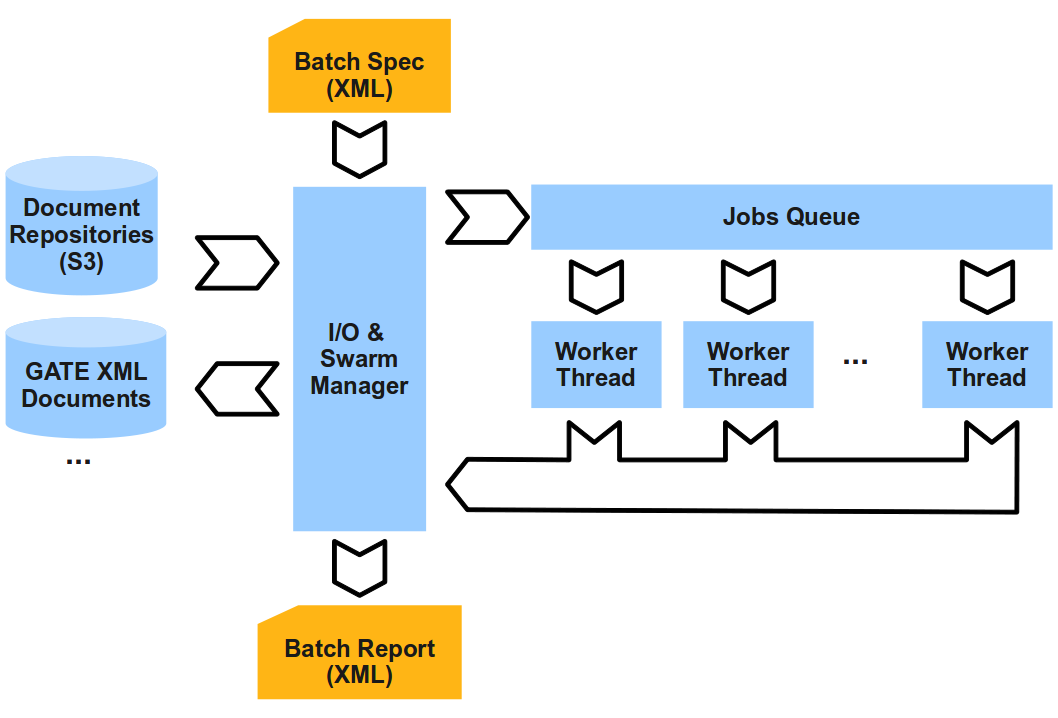
|
GATE Cloud (3): the research point
- something like the facility that the the IRF was trying to set up for IR
more generally
- host a growing family of experimental system configurations, data sets,
results
- biased heavily towards information extraction (perhaps some mileage in adding
more mainstream IR?)
- persistence and reuse of experimental setups: virtualisation makes it possible
to store not just data but the entire compute platform operable for particular
experiments or analyses
First Cousins -- the Ontotext family
Complementing the GATE tools KIM provides a straightforward front-end deployment
option and their Linked Data offerings a good baseline for model building:
- Ontotext KIM: UIs demonstrating multiple
conceptual and facetted search modes
- Ontotext OWLIM: the fastest and most
scaleable semantic repository
- Ontotext FactForge: ~4 billion statements
from the Linked Data cloud
- Ontotext Linked Life Data: over 4 billion
statements from life sci databases including UniProt, PubMed, EntrezGene and
20 more
GATE Mímir: hitting the indexing problem
|
Circa 2007:
- A new project on patent searching at the IRF =
culture shock!
- Full text, boolean ("100% recall"!)
- Initial prototyping and demo work:
- Conceptual and semantic search and navigation (KIM, as above)
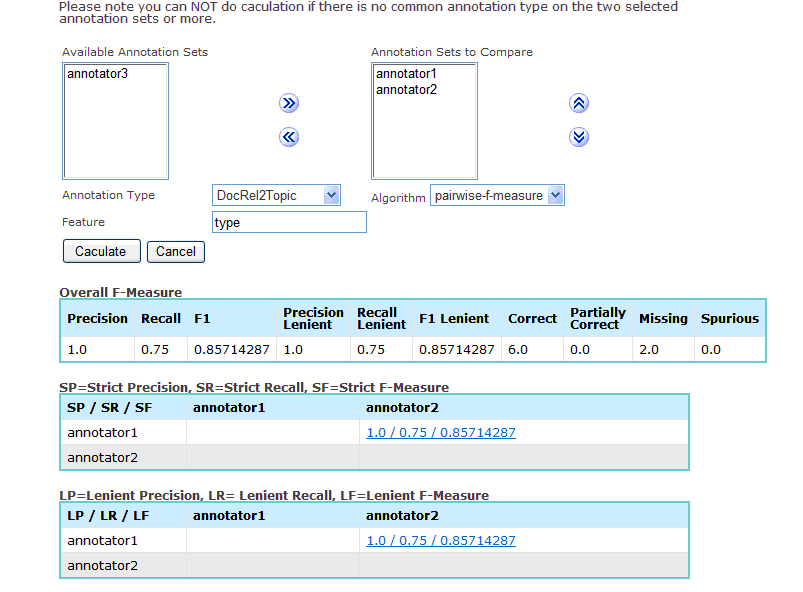
- ANNotations In Context (ANNIC) (right)
- User requirement: put it all together
- Ooops: ANNIC scaled to 200 short docs...
|
ANNIC (ANNotations In Context):
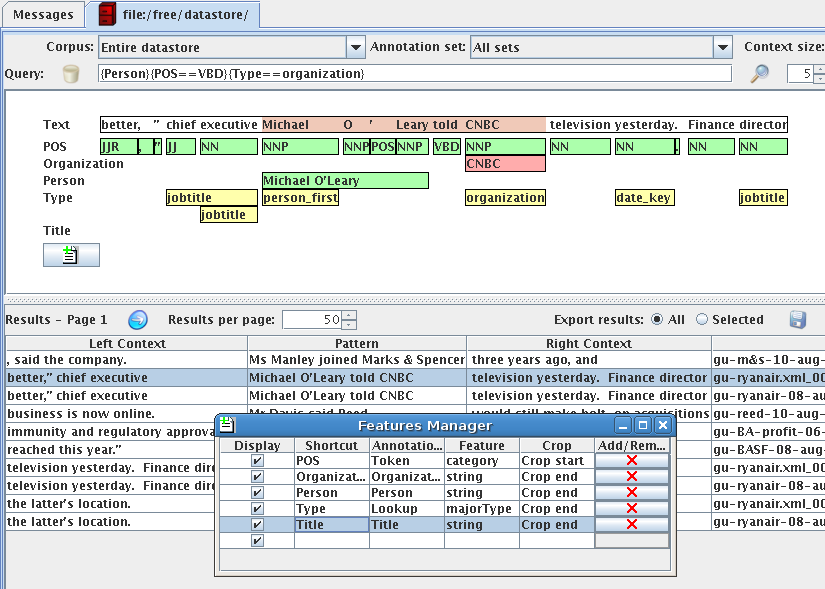
|
Annotations: the Missing Data Structure (1)
|
How do we search a billion-node annotation graph...?
| |
Model:
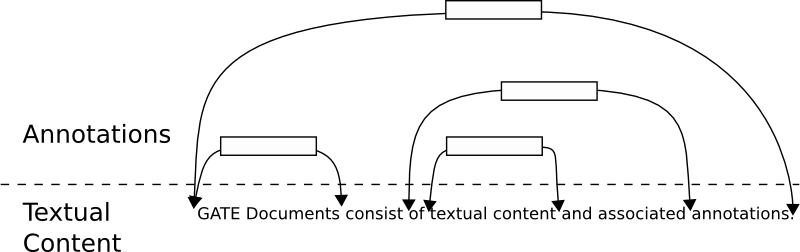
| |
(Cf. TIPSTER, TEI/XCES, ATLAS, UIMA, ...)
|
| |
UI example:
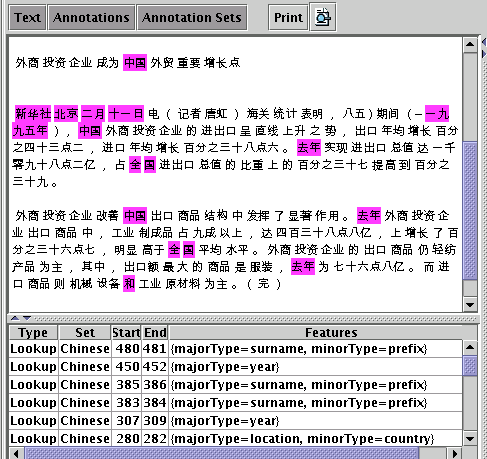
|
Annotations: the Missing Data Structure (2)
- Our first thoughts: where can we steal one?
- Annotations: how to index the graph?
- XML indexing and retrieval work doesn't solve it (biased towards trees)
- RDBMS doesn't solve it (biased towards relations)
- augmented full-text indices can help with efficient access, but the data
storage requirements of our prototype (based on Lucene) grew exponentially
with the cardinality of the annotation sets
- May 2008: workshop on Persisting, Indexing and Querying Multi-Paradigm Text
Models, IRF, Vienna
- MG4J (Eric Graf, Glasgow)
- Terrier (Gianni Amati, FUB/Glasgow)
- INEX (Norbert Fuhr, Essen-Duisburg)
- KIM, OWLIM (Atanas Kiryakov, OntoText)
|
- ANNIC (Valentin Tablan, Sheffield)
- HTML-XML Search Engines (Ralf Schenkel, MPG)
- Monet DB (Arjen de Vries, CWI)
|
- May 2009: custom solution based on MG4J (Sebastiano Vigna) + OWLIM called
Mímir...
- May 2010: version 2: incremental indices; federation
- May 2011: version 3: full source release under the AGPL; cloud release
Mímir: Multi-paradigm Information Management Index and Respository
Mímir is an index engine that can search over:
- text
- textual and semantic annotations
- ontologies and knowledge bases
Built on top of:
- the MG4J text indexing library
- GATE's annotation index (remodelled in MG4J)
- Ontotext's semantic repository family
(Just about) scales to a terabyte of annotated text
More information: some query
examples; demos;
user and developer guide
The Poor Relation: GATE Wiki (1)
Why another wiki? Scratching three itches:
- adding interaction to a largish static site (15k HTML files, 40k other
files)
- wiki style collaborative document creation with asynchonous off-line editing
- a test-bed for experiments in controlled languages for round-trip ontology
engineering
Hence CoW, a Controllable Wiki (aka GATEWiki): http://gate.ac.uk/gatewiki/cow/
GATE Wiki (2)
Main features
- designed from the ground up to support concurrent editing and off-line
working with straightforward synchronisation using Subversion (SVN)
- uses the YAM language, which
- outputs LaTeX as well as HTML
- allows paths as links (i.e. does not limit the namespace to a single
directory like e.g. JSPWiki does) and consequently allows a
tree-structured page store (and later graph-structured navigation via an
ontology)
- allows mixing of all types of files in its page store (which is just an SVN
sandbox, in fact)
- supports versioning and differencing via SVN, and allows other tools that
manipulate SVN repositories to be used with the wiki data (e.g. SVN itself,
Eclipse, ViewCVS, etc.)
- may optionally support embedded CLOnE
(Controlled Language for
Ontology Editing), and therefore experiments with applications that store
their data in semantic repositories whose schema is user-defined and
maintained
Contents
- 1. Background: the GATE family
- Developer, Embedded
- Teamware, Process
- Cloud
- KIM, OWLIM, Linked Data
- Mímir
- [Wiki]
- 2. Demos
[3. Case studies]
- [IARC: the WHO's cancer lab]
- [TNA: UK National Archives]
- [SLaM: NHS clinical records mining]
4. A lifecycle for text analysis
Contents
- 1. Background: the GATE family
- Developer, Embedded
- Teamware, Process
- Cloud
- KIM, OWLIM, Linked Data
- Mímir
- [Wiki]
- 2. Demos
- [an IDE for text analysis specialists]
- [collaborative manual annotation workflows]
- GATECloud.net
- Mímir: a mixed-mode index server
- [3. Case studies]
- [IARC: the WHO's cancer lab]
- [TNA: UK National Archives]
- [SLaM: NHS clinical records mining]
4. A lifecycle for text analysis
Genome-Wide Association Studies at the WHO (1)
World Health International Agency for Research in
Cancer, the world's biggest cancer epidemiology lab.
Genetics groups: which mutations (SNPs) associate with carcinogenesis?
New trends in genetic association studies (stimulated by decreased cost of
sequencing):
- objective: identify common genetic variants involved in susceptibility to
disease
- candidate gene approach: genes selected and tested based on prior
knowledge/hypotheses
- GWAS approach: test “all” common genetic variants with no prior
knowledge/hypothesis
GWAS (2)
The problem: needle (significant associations) in a haystack (large-scale
gene sequence probes)
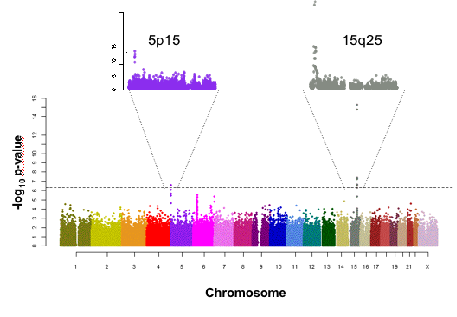
GWAS (3)
The WHO results
- Nature paper 2008: GWAS result showing a particular genetic
polymorphism correlates with increased risk of lung cancer in smokers
- required a large amount of manual work to examine data from sensor arrays
- the usual statistical techniques need large numbers of samples to make the
analysis usable and reliable
An annotation experiment
- our experiment used Bayesian False Discovery Probability (BFDP) to take into
account prior knowledge about genes
- e.g. if a gene is expressed in lung tissue, represent this in the BFDP model
when calculating relevance of sensor data for related polymorphisms
- prior knowledge about genes is buried in scientific papers, so we use
annotation to find papers that discuss particular genes, diseases, anatomy and
so on (AdAPT -- Adjusting Association Priors with Text)
- able to find genes associated with lung cancer using half the data needed by
the typical statistical techniques (potential saving: €250k)
2010: applied to head and neck cancer and found a new association
The National Archives (TNA) of the UK (1)
- UK government's official archive, containing over 1,000 years of data in > 11
million records
- Government web archive project aims to help open up TNA's records of .gov.uk
websites (going back through 1997 and comprising some 340 million pages)
- Government funding has been allocated to publishing more and more material on
data.gov.uk in open and accessible forms
- But it's still pretty hard to find the information you're looking for
- Aim is basically to improve access to this enormous volume of data -- both for
the general public and for specialist researchers
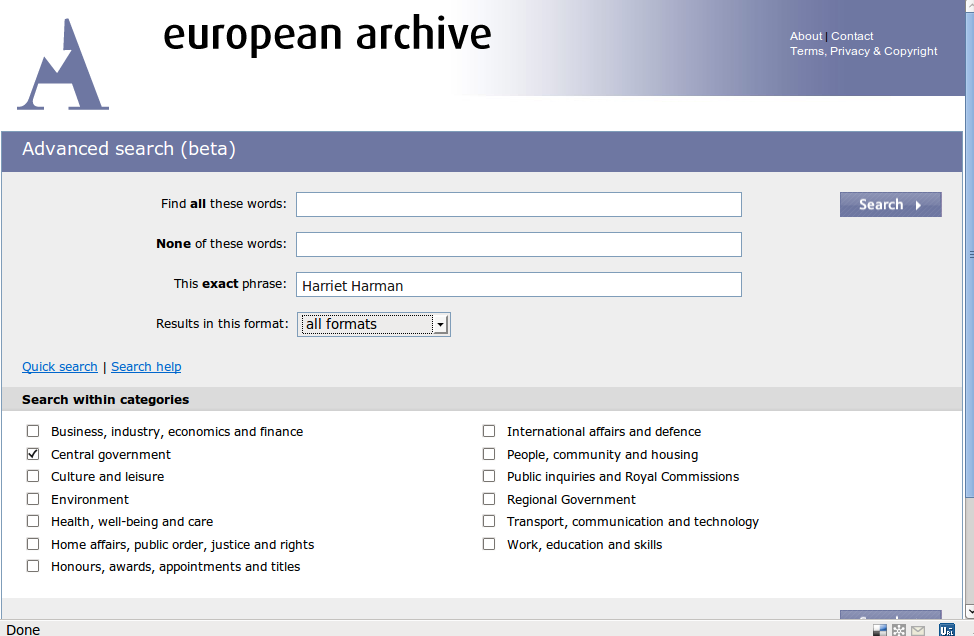
TNA (2): current search facilities
TNA (3): new facilities
- Enable semantic-based search for categories of things, e.g. all Cabinet
Ministers, all cities in the UK
- Search results include morphological variants of words and synonyms
- Search for specific phrases with some unknowns, e.g. a Person and a monetary
amount in the same sentence
- Search for ranges, e.g. all monetary amounts greater than a million pounds
- Restrict search to certain date periods, domains etc.
Method:
- Import/store/index structured data in a scalable semantic repository data
relevant for the web archive (using linked data principles; in the range of
tens of billions of facts)
- Make links from web archive documents into the structured data
- Allow browsing/search/navigation
- from the document space into the structured data space via semantic
annotation and vice versa
- via a SPARQL endpoint
- as full text and as linguistic annotation structures
TNA (4): architecture
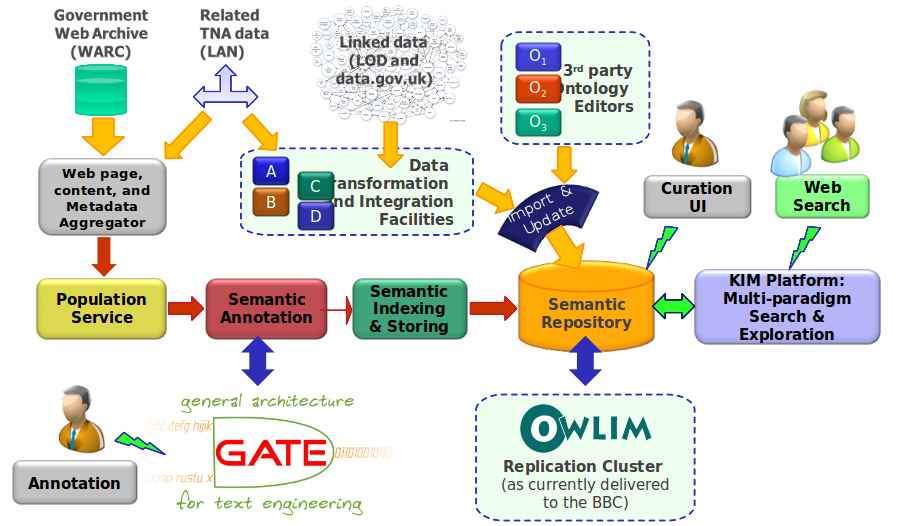
TNA (5): annotation types
- General NEs:
- standard ANNIE NEs (with some additional features, e.g. date normalisation)
- Measurements:
- measurement (dimension, type, unit, value, normalised, scalar, interval)
- ratio (value)
- Posts:
- cabinet, civil service, military, medical, other (e.g. MP, CEO)
- Official Documents
- legislation, other (e.g. white paper)
- Projects/Initiatives/Campaigns
- Wars/Military Conflicts
South London and Maudsley NHS Trust (1)
Mining clinical records
- The user:
- SLAM: South London and Maudsley NHS Trust
- BRC: Biomedical Research Centre
- CRIS: Case Register Information System
- February and March 2010:
- Proof of concept around MMSE
- Requirements analysis, installation, adaptation
- Since then:
- In production
- Further use cases: smoking, diagnosis
- Several development functions taken in-house
NHS (2)
|
Mini Mental State Exam
- Generic entities such as anatomical location, diagnosis and drug are sometimes
of interest
- But many of the enquiries we have seen are more often interested in large
numbers of very specific, and ad hoc entities or events
- This example is with a UK National Biomedical Research Center
- An example – cognitive ability as shown by the MMSE score
|
Some results:
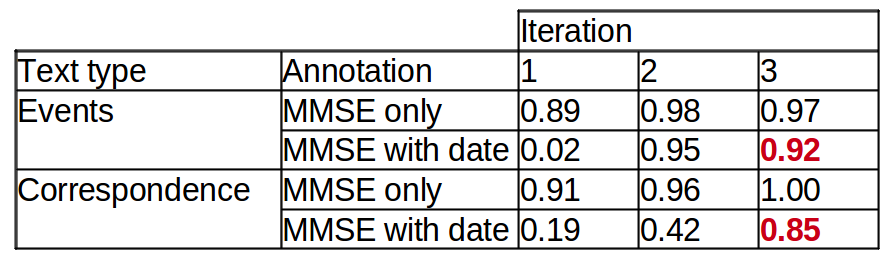
|
NHS (3)
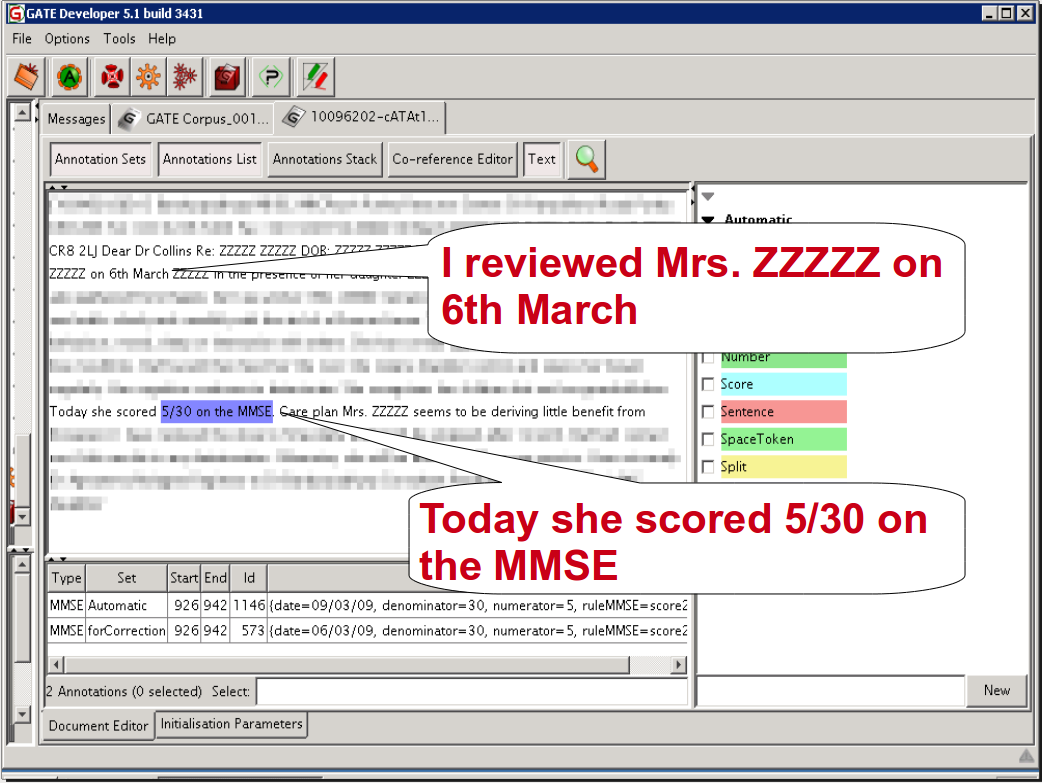
Contents
- 1. Background: the GATE family
- Developer, Embedded
- Teamware, Process
- Cloud
- KIM, OWLIM, Linked Data
- Mímir
- [Wiki]
- 2. Demos
- [an IDE for text analysis specialists]
- [collaborative manual annotation workflows]
- GATECloud.net
- Mímir: a mixed-mode index server
- [3. Case studies]
- [IARC: the WHO's cancer lab]
- [TNA: UK National Archives]
- [SLaM: NHS clinical records mining]
- 4. A lifecycle for text analysis
Full lifecycle information extraction
How it all hangs together:
- Take one large pile of text (documents, emails, tweets, patents, papers,
transcripts, blogs, comments, acts of parliament, and so on and so forth).
- Pick a structured description of interesting things in the text (a telephone
directory, or chemical taxonomy, or something from the
Linked Data cloud) -- call this your ontology.
- Use GATE Teamware to mark up a gold standard example set of
annotations of the corpus (1.) relative to the ontology (2.).
- Use GATE Developer to build a semantic annotation
pipeline to do the annotation job automatically and measure performance
against the gold standard.
- Take the pipeline from 4. and apply it to your text pile using
GATE Cloud (or embed it in your own systems
using GATE Embedded). Use it to bootstrap more manual
(now semi-automatic) work in Teamware.
- Use GATE Mímir to store the annotations relative to the
ontology in a multiparadigm index server.
- (Probably) write a half-decent UI to go on top of Mímir.
- Hey presto, you have search that applies your annotations and you
ontology to your corpus (and a sustainable process
for coping with changing information need and/or changing text).
- Your users are happy (though possibly also broke :-().